Automated Analysis anD Scoring of Student Writing
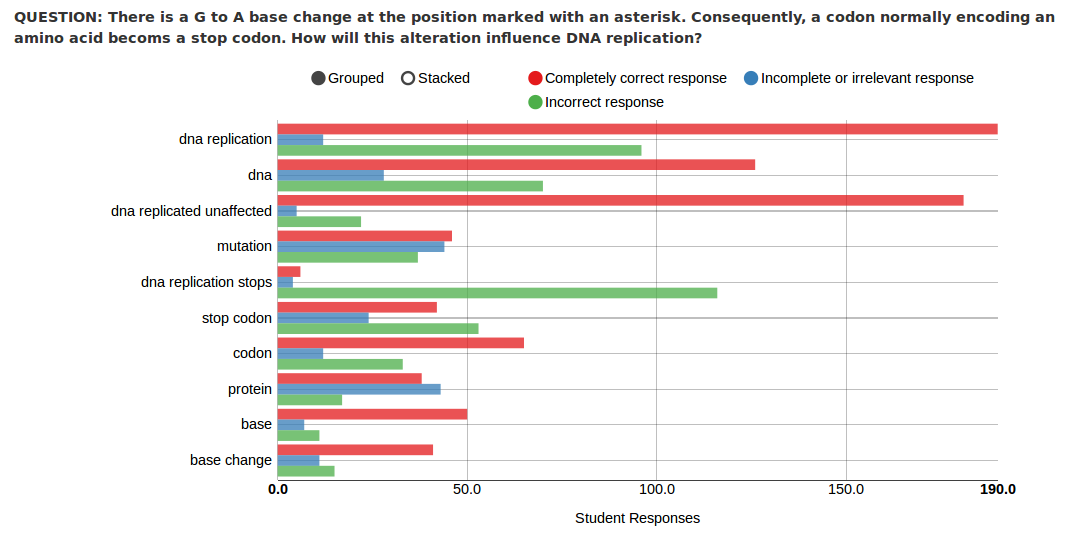



Multiple choice questions have long been a fixture in large introductory level science courses. They are quick to grade and clean and easy to analyze. Unfortunately, the insight they can provide into student thinking is limited. If a multiple choice question is well constructed and rigorously validated it will have one correct answer. Even the best constructed question, however has an infinite number of ways it may be answered incorrectly. The multiple choice format forces students to select from a small handful of incorrect possibilities, none of which may represent what they actual think about the topic. To further complicate the issue many student will have a chimera of thought in there heads composed correct and incorrect conceptions all jumbled together. In the best case a multiple choice question provides a spot check if the student thinks what one hopes or fears they do. In any other case they merely force the student to select the idea which is least dissimilar to the one that lives in their heads.
An alternative tack to discovering how student think about any given concept is to ask them directly. Open ended questions (known as "constructed response" questions) provide student the opportunity to communicate there thoughts in there own words. Traditionally the barrier to constructed response questions in the science classroom has been a matter of logistics. These items are much more time consuming to score and analyze than their multiple choice counterparts. In introductory courses that have enrollments in the hundreds, the analysis costs are prohibitive.
Once possible solution to this problem is provided by predictive analytics. By training a computer to evaluate student responses to open ended questions it is possible to reduce the logistic costs of constructed response questions to be comparable to that of multiple choice questions. Further automated analysis and reporting can provide instructor a deeper and more complete picture of how even the largest of classes thinks about the course contents.
Multiple Populations in Globular Clusters

Photo Credit: NASA, ESA, and The Hubble Heritage Team (STScI/AURA)
Globular clusters, like the one on the left, are collections of about 10,000 to 1 million stars packed together in a tight ball. Because we in the astronomy community are nothing if not clever namers of things, a cluster of stars that looks like a 'glob' is referred to as a 'globular cluster'. For years we astronomers believed that all the stars in a globular cluster formed at about the same time, from the same cloud of gas. Because these stars share a single birthdate and are made of the same combination of gases, effectively comprising one generation, we say they are part of a single population of stars.
Since things are rarely as simple as they first appear, astronomer have discovered in the past decade or so that globular clusters appear be made of not just one generation of stars, but two, three, or even more. What seems to be happening is that as the stars in the first generation age they eject some of their gas back into space. Once enough gas is ejected from the stars in the cluster, and second generation is born from the resulting cloud, recycling the gas. A cluster that has more than one generation of stars is said to have multiple populations.
So far all the multiple population globular clusters that have been found are in our Milky Way Galaxy. That's handy since Milky Way Clusters are relatively close to us and easy to study. The problem is if we want to understand why and how globular clusters form multiple generations we need to find a large number of multiple generation clusters. To do that we have to look outside the Milky Way to globular clusters in other galaxies. This is tricky because globular clusters in other galaxies are far away, and we are unable to see the individual stars that make up cluster. We can only collect the combined light of all the stars in the cluster. In my research I am working on finding ways to determine if these distant globular clusters are made of one generation or multiple populations.
Outflows from Accreting Black Holes

Matt's representation of an outflow from a black hole
Black holes are dark. Very dark. Extremely dark. Mind bogglingly dark. Black holes are dense. They are so dense and have such strong gravity that light itself can't escape their clutches, which makes them very dark. Any light which gets too close gets pulled in and disappears as though it fell down a dark hole. (See aren't we astronomers great at naming things?) This is all very cool, but makes things difficult if you want to study them.
If one is keen on studying black holes observationally, as I and many other astronomers are, then means of study other than looking directly at them must be used. Fortunately there are a number of different techniques that may be used to observationally study black holes, most of which involve watching how black holes interact with stuff we can see. Smallest black holes (those which are several times more massive than the sun) are sometimes found in pairs with regular stars. The black hole and regular star can orbit around each other with no ill-effects to either party for a good long while. Occasionally though, the pairs orbit get a little too close and the black hole's gravity strips the outer layers of gas from it's companion. Some of that gas falls into the black hole via a process astronomers call accretion, but most of it is ejected at very high velocities back into space.
My research is focused on the gas that is ejected from the black hole system called and an 'outflow' (becasue it flows out of the system--aren't we clever). Studying these outflows can tell us about the black hole-regular star pair, the accretion process, and the mechanism by which the gas is ejected.
Large Data Set Science









We are living during the early days of large data set science. Over the past few decades technology has allowed us to collect and store quantities of information hitherto unknown in human history. These enormous chunks of data are being accumulated by the fields of science, business, and technology at a rate that is currently outstripping our ability to fully digest all the insights they have to offer. I believe that we in the astronomy community have quite a bit to offer the broader 'Big Data' field.
The figures above come from a analysis I performed as performed as part of the testing of the SDSS SEGUE data reduction pipeline commissioning. The SEGUE program was one of the first major large data set programs devoted to Milky Way stellar astronomy. My multivariate analysis of some 15,000 targets examined the stellar populations of the sample and compared the data set to expectations from simulated observations.